zur Erweiterung/Verschönerung unserer pulverbeschichteten Alu-Möbel
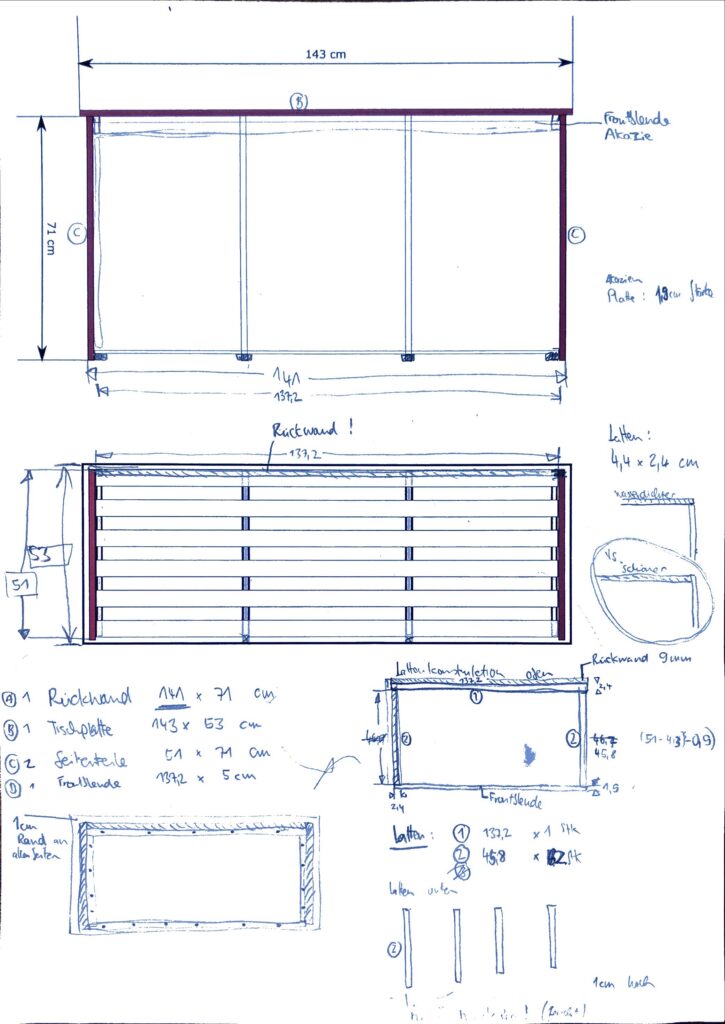



zur Erweiterung/Verschönerung unserer pulverbeschichteten Alu-Möbel
Mai 2020



When installing VMWare tools in my Mavericks VM, I got an error that VMWare tools can’t be installed due to an expired certificate. (resetting the clock doesn’t help… 😉
VMWare Tools can be downloaded from VMWare update server, e.g.:
https://softwareupdate.vmware.com/cds/vmw-desktop/fusion/11.5.3/15870345/core/
The downloaded TAR contains a ZIP.
The ZIP contains the OSX Fusion app.
The Fusion app (in its package content) contains the VMware tools ISO files.
darwin.iso for newer OSX versions.
darwinPre15.iso for older OSX versions, such as Mavericks
The full paths are:
com.vmware.fusion.zip\com.vmware.fusion\payload\VMware Fusion.app\Contents\Library\isoimages\darwin.iso
com.vmware.fusion.zip\com.vmware.fusion\payload\VMware Fusion.app\Contents\Library\isoimages\darwinPre15.iso
Mount the according ISO image to your client, install VMWare tools.
ping ubuntu1804server ping: cannot resolve ubuntu1804server: Unknown host
can be solved by installing libnss-mdns in the guest OS.
The guest can now be addressed by
ping ubuntu1804server.local
Passend zur beliebten Spielküche eines bekannten Möbelherstellers









Since Plex offers offical packages for raspberry systems, installing plex got really easy. The official installation documentation can be found here but misses a few steps when setting up on a freshly setup raspi:
curl https://downloads.plex.tv/plex-keys/PlexSign.key | sudo apt-key add - sudo apt install apt-transport-https echo deb https://downloads.plex.tv/repo/deb public main | sudo tee /etc/apt/sources.list.d/plexmediaserver.list sudo apt-get update sudo apt-get install plexmediaserver
sudo apt-get install exfat-fuse exfat-utils
UUID=5B86-AAAA /media/Malaga exfat defaults,auto,umask=000,users,rw,uid=pi,gid=pi 0 0
Then remount all mount points:sudo mount -a
Are you trying to finally get rid of your old laptop, but don’t know if it contains still some data that might be relevant some day? If it still runs, just boot it up with a recent Knoppix boot medium and backup its data.
The default settings of mkisofs can’t handle deeply nested paths well, so I suggest the following parameters:
mkisofs -input-charset iso8859-1 -iso-level 4 -udf -o /path/to/destination.iso -V your_volume_label /directory/to/backup
Note: For easy handling of the data in OSX, you should copy the ISO file to a backup disk that’s formatted with exFAT filesystem.
The open source tool Subler offers a perfect feature to convert VobSub captions to TX3G format that is more compatible to iTunes and other clients (like Plex).
But the stock version of Subler only supports English text recognition. In order to recognize German umlauts and other latin special characters like this, you need to download extra data files for the OCR library ‘tesseract’.
Subler’s documentation mentions that but the link is outdated. So here’s the correct link to the data files for the (old) tesseract lib that’s included in Subler:
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-302
The tar files have to be unpacked and the data has to be copied to ~/Library/Application Support/Subler/tessdata
I used TagSoup some years ago, but last week I came across ‘JSoup’. It also allows parsing of ‘real world HTML’, and comes with a really neat API to download and select subsets of your document.
See for yourself:
String url = “https://javaspecialists.teachable.com/p/refactoring2j8”;
Document doc = Jsoup.connect(url).get();
Elements items = doc.select(“a.item”);
You must be logged in to post a comment.